[SL] Metriken für agile Teams - den Prozess verbessern und Vorhersagen machen
Auf dem Agile Camp Berlin waren wir auf einer spannenden Session von Anastasia Lipkina zum Thema “KPIs / Time Predictability”. Es ging darum, welche Metriken oder Key Performance Indicators (KPIs) für ein Team in der agilen Softwareentwicklung angewandt werden sollten, und wie man vorhersagen kann, wann bestimmte Aufgaben (oder ganze Projekte) fertig sind. Gestern hatte ich die Metrik “Running Tested Features” (RTF) vorgestellt. Dabei nähern wir den erwarteten Kundennutzen an durch die Anzahl von fertigen Features. Diese müssen Teil der laufenden (gelieferten) Software sein (“running”) und natürlich alle Tests absolviert haben (“tested”).
Wie gestern gesagt, kann man mit Metriken zwei Ziele verfolgen: Den Prozess verbessern, oder eine Vorhersage zur Fertigstellung machen.
Ziel 1: Den Software-Lieferprozess verbessern
Der Artikel “A Metric Leading to Agility” von Ron Jeffries beschreibt nicht nur die Metrik RTF, sondern auch, wie die RTF-Kurve über die Projektlaufzeit aussehen sollte: von Anfang an wird geliefert, und die Anzahl “Running Tested Features” steigt gleichmäßig an. Wenn die Kurve stagniert, oder zwischenzeitlich absackt, haben wir ein Problem, das untersucht werden muss. Für Details empfehle ich den sehr lesenswerten Artikel.
Das ist natürlich nicht alles, denn RTF misst ja nur ziemlich am Ende des gesamten Prozesses, und Bugfixes sowie technische Aufgaben werden nicht erfasst. Für die Zwischenstufen empfiehlt sich ein Cumulative Flow Diagram:
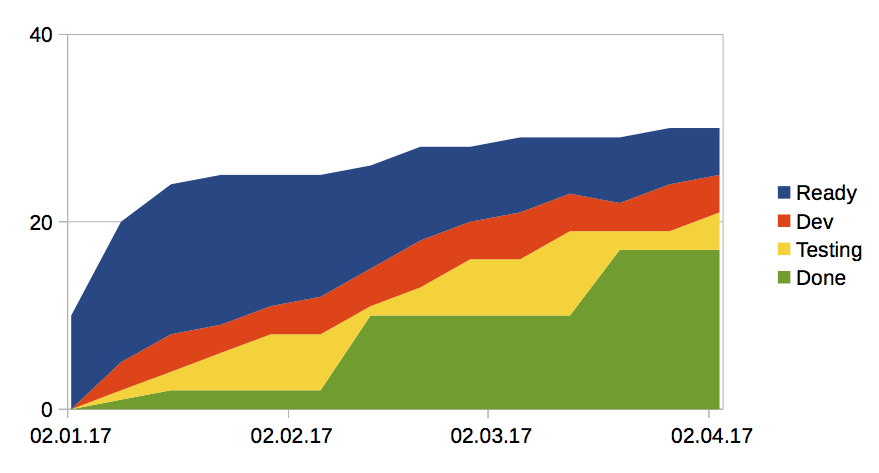
Die Anzahl “Work Items” (User Stories, Tickets usw.) steht auf der y-Achse, Zeit ist die x-Achse. Die Anzahlen für die einzelnen Phasen werden übereinander gestapelt (deswegen heißt das Diagramm “kumulativ”). Die Reihenfolge der Phasen ist wichtig: die erste Phase ist die oberste Schicht (z.B. “Ready”), dann kommt die zweite Phase (z.B. “Development”), und die letzte Phase (“Done”) ist ganz unten. Die Dicke der einzelnen “Schichten” im Diagramm gibt an, wieviele Work Items sich in der jeweiligen Phase befinden. Die oberste Grenze des Diagramms zählt alle Aufgaben im System. Hier steigt diese Linie (obere Grenze der blauen Fläche) bis Mitte Januar stark an, weil wir die Aufgaben für das Projekt noch definieren. Im Projektverlauf steigt die Gesamtzahl noch langsam weiter, weil wir z.B. neue Anforderungen entdecken oder Bug Reports bekommen.
Das Cumulative Flow Diagram zeigt also, wie die Arbeit durch die einzelnen Phasen fließt (Flow). Es “sieht gut aus”, wenn die einzelnen Schichten möglichst dünn sind, denn dann haben wir kurze Warteschlangen und folglich auch kurze Durchlaufzeiten (Little’s Law).
Im obigen Diagramm sieht man zum Beispiel, dass die Kurve für “Done” (grüne Fläche) nicht gleichmäßig wächst, sondern zweimal einen Sprung macht und dann wieder stagniert. Entsprechend dazu wächst der Bestand an Tickets in der Phase “Testing” (gelbe Fläche) an, bis er schließlich sprunghaft abgebaut wird. Das kann daran liegen, dass Testkapazität nicht gleichmäßig zur Verfügung steht, oder dass nur alle paar Wochen eine “Abnahme” gemacht wird. Wie auch immer, wir haben hier eine Möglichkeit, den Software-Lieferprozess zu verbessern: gleichmäßigeres Abarbeiten in der Phase “Testing” würde die Durchlaufzeiten verkürzen.
Weitere Beispiele gibt es in “Cumulative Flow Diagrams kurz erklärt” und “Engpässe erkennen per Cumulative Flow Diagram”.
Apropos Durchlaufzeit: das ist die Zeit, die ein Ticket in der Abarbeitung bzw. in einer Phase verbringt. Solche Zeiten zu messen ist natürlich sinnvoll:
- Cycle Time ist die Durchlaufzeit, vom Beginn der Bearbeitung bis zum Ende. Das kann man noch auf einzelne Phasen beziehen, etwa “Für das Testen haben wir eine Cycle Time von durchschnittlich 2 Wochen”.
- Lead Time ist die Zeit, die vergeht von der “Bestellung” bis zur Auslieferung. Das kann Wartezeiten beinhalten, wenn wir z.B. die Anforderung erstmal in’s Backlog stellen, statt gleich daran zu arbeiten.
Für einen Report gibt man am besten die Durchlaufzeiten mit Perzentilen an, zum Beispiel: “50% unserer Tickets haben weniger als 4 Wochen Durchlaufzeit (von Ready bis Done), und 95% unserer Tickets brauchen weniger als 10 Wochen”.
Ausreißer in der Durchlaufzeit sollte man sich genauer ansehen. Was hat so lange gedauert? Gibt es Hindernisse, die wir systematisch abbauen sollten? (“Die Rechtsabteilung braucht immer mindestens 4 Wochen, bevor sie unsere Änderungen in den AGB genehmigt”)
Wenn man allerdings den Prozess steuern will, ist es besser, mit Anzahlen (Länge der Warteschlange, WIP) zu arbeiten. Das liegt daran, dass man eine Veränderung der Durchlaufzeit erst im Nachhinein sieht, während die Warteschlange schon “im laufenden Betrieb” länger oder kürzer wird. Der beste Hebel für Verbesserungen ist auch hier, das WIP (work in process) zu begrenzen. Die entsprechenden Anzahlen für die einzelnen Phasen des Software-Lieferprozesses sieht man im Cumulative Flow Diagram.
Und was ist mit Velocity, also Anzahl fertiggestellter Story Points pro Woche bzw. pro Iteration? Ich sehe nicht viel Mehrwert in der Schätzung von Story Points. Die Aufgaben (User Stories, Tickets) müssen nur hinreichend klein zerlegt sein, dann reicht es, sie zu zählen, man muss nicht noch zusätzlich mit Story Points gewichten.
Ein paar weitere Metriken gäbe es noch, die man einsetzen kann, um einen Missstand zu verdeutlichen bzw. eine Verbesserung zu steuern. Für Qualität wäre das zum Beispiel der Anteil Arbeitszeit, der auf die Behebung von Fehlern entfällt. Oder die Anzahl Fehler, die uns aus dem Produktivbetrieb zurückgemeldet werden.
Wenn man Releasezyklen kürzer machen will, lohnt es sich, die “Rüstkosten” zu bestimmen. Das ist die Zeit, die für den mit dem Release verbundenen Overhead (manuelles Testen, Deployment usw.) aufgewendet werden muss. Für häufigere Releases wird man diesen Aufwand systematisch verringern müssen.
Ziel 2: Vorhersagen machen, wann etwas fertig ist
Wenn wir in gleichbleibender (oder leicht ansteigender) Geschwindigkeit “Running Tested Features” liefern können, werden auch Prognosen ziemlich zuverlässig möglich. Wichtig ist eben, dass der Entwicklungs-Prozess stabil ist, und dass es möglichst keine späten Überraschungen gibt. Dazu muss ich hier nicht viel sagen, die Herangehensweise ist in “Was ist #NoEstimates? Projekte steuern ohne Schätzungen” beschrieben.
Mit Metriken für Transparenz und Motivation sorgen
Die Metriken eines Teams sollten für alle verständlich und gut sichtbar sein. Das entspricht dem Prinzip des “Information Radiator”, das schon früh in den agilen Methoden empfohlen wurde. Im Lean Thinking gibt es ein ähnliches Konzept: Visual Management – es ist für alle auf einen Blick zu erkennen, wie das Team dasteht.
Außerdem sollte man den Verlauf einer Metrik über die Zeit anzeigen. Dann entwickeln alle ein intuitives Gefühl für die zufälligen Schwankungen einer Metrik von Woche zu Woche und geraten nicht gleich in Aufregung, wenn es mal einen Ausschlag nach oben oder unten gibt.
Metriken zu erheben und die Charts aktuell zu halten macht Arbeit, wählen Sie also möglichst wenige Metriken aus. Es ist normal, dass ein Team im Laufe eines Projekts unterschiedliche Metriken braucht. Was sich nicht bewährt, sollte ausrangiert werden. Dafür kommt manchmal eine neue Metrik hinzu, sobald ein anderer Aspekt des Prozesses verbessert werden soll.
Matthias Berth