[SL] Lesenswert: State of DevOps 2019
Im August wurde die diesjährige Version des “Accelerate - State of DevOps” Reports veröffentlicht (direkter Download des PDFs). Auf 86 Seiten werden gut aufbereitete Daten präsentiert, leicht lesbar durch ansprechendes Design, eben die erwartbare Mischung aus “harten Fakten” (Ergebnissen der empirischen Untersuchung) und griffigen Zusammenfassungen, garniert mit ein paar Ratschlägen und Infografiken. Die Zusammenfassung im Google Blog beschreibt die wichtigsten Erkenntnisse.
Wo stehen wir?
Es wird mit empirischen Methoden untersucht, wie es um die Software Delivery and Operational Performance (SDO) von Organisationen im Jahre 2019 steht. Die Kompetenz, Software zu liefern, wird wiederum als entscheidend betrachtet für den Gesamterfolg einer Organisation
We see continued evidence that software speed, stability, and availability contribute to organizational performance (including profitability, productivity, and customer satisfaction).
Wie in den letzten Jahren auch teilen sie die ca. 1000 Befragten in vier Cluster (“performance profiles”) ein, Elite (20% der Befragten), über High und Medium bis Low (12%).
Die Autoren beschreiben vier Metriken, die sich gut als Ziele für kontinuierliche Verbesserung eignen:
- Vorlaufzeit (Lead Time), hier definiert als die Zeit vom Einchecken einer Code-Änderung bis zur Auslieferung im Produktivbetrieb. Die Besten (“Elite”) brauchen weniger als einen Tag Vorlaufzeit, wer zwischen einem und sechs Monaten braucht, findet sich im Cluster der “Low Performers” wieder.
- Häufigkeit von Releases (Deployment frequency), die Messlatte hängt bei mehrfach täglich, “Low” beginnt bei einmal pro Monat oder seltener.
- Die Zeit bis zur Wiederherstellung nach Ausfällen (Time to restore service) variiert von weniger als einer Stunde (Elite) bis zu mehr als einer Woche (Low).
- Der Anteil an fehlgeschlagenen Änderungen (Change failure rate) misst, wie häufig eine Änderung im Code freigeschaltet wird, die z.B. einen Ausfall, eine teilweise Einschränkung des Services oder einen Hotfix nach sich zieht. Hier liegen die “Low Performer” bei 46-60%, alle anderen bei 0-15%.
Der Report eignet sich also gut als Argumentationshilfe und zur Beantwortung der Frage “Wo stehen wir eigentlich?”.
Wie können wir besser werden?
Daneben werden Einflussfaktoren empirisch untersucht: Welchen Einfluss haben z.B. automatisiertes Testen oder Wartbarkeit des Codes (Refactoring) auf die Software Delivery and Operational Performance? Die Ergebnisse sind etwa “Wartbarkeit des Codes hat einen positiven Einfluss auf Continuous Delivery, was wiederum positiv auf Software Delivery Performance und Availability wirkt.” Jede einzelne Ursache-Wirkungs-Beziehung ist statistisch belegt, als Zusammenfassung bekommt man ein Diagramm:
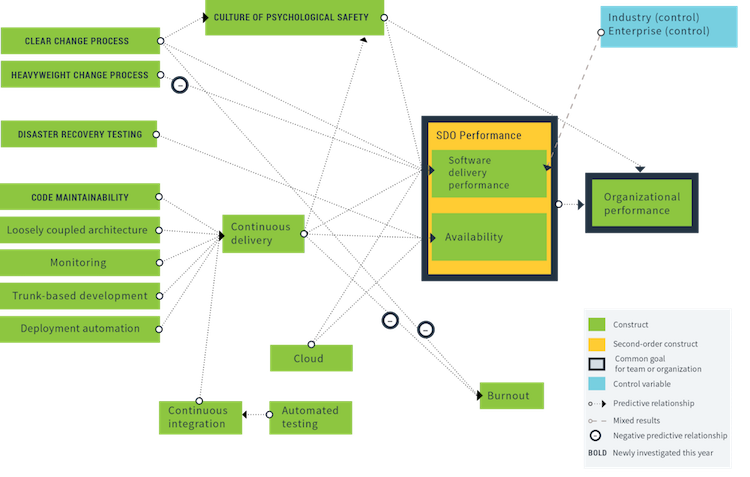
(Quelle: Accelerate - State of DevOps 2019, S.31)
Ein paar Fußnoten
Wir bei SoftwareLiefern.de betrachten den gesamten Prozess “Von der Idee bis zur Umsetzung”. Die Studie setzt aber erst bei der eigentlichen Softwareentwicklung an, die Vorlaufzeit (Lead time) beginnt erst, wenn der Code eingecheckt ist. Wenn man bedenkt, wie lange manchmal Anforderungen liegen bleiben können, bevor auch nur eine Zeile Code geschrieben ist, kann die Zeit “Von der Idee bis zur Umsetzung” auch bei den “Elite Performern” immer noch sehr lang sein.
Auch die Messung des Geschäftsnutzens einer ausgelieferten Änderung wird nicht berücksichtigt: Gibt es etwa A/B-Tests, um die Auswirkung eines neuen Features auf den Umsatz zu bestimmen? Wie ist das Feedback von Endanwendern organisiert? Beide Aspekte (Vorlaufzeit von Idee bis Code und die Messung des Effekts) wären interessant gewesen. Man kann das den Autoren nicht vorwerfen, es gibt immer weitere Fragestellungen, die man nicht mehr abarbeiten kann.
Wie bei vielen Studien kann man schon mit der Auswahl der Befragten viel falsch machen. Eine repräsentative Stichprobe (“1000 Softwareleute zufällig aus der weltweiten Population ausgewählt”?) ist unmöglich zu bekommen. Die Autoren haben sich bemüht, indem sie nach dem Schneeballsystem Leute für ihre Umfrage rekrutiert haben. Der Befund “Im Vergleich zum letzten Jahr haben wir eine signifikante Verringerung des Anteils von Frauen in Teams beobachtet” könnte einfach ein zufälliges Ergebnis der jeweiligen Stichprobe sein. Man kann auch einwenden, dass DevOps-Fans in einer Umfrage über DevOps überdurchschnittlich vertreten sein werden, das hieße dann, dass hier der Status Quo etwas zu rosig dargestellt wird.
Ich habe leider nicht genug statistisches (psychometrisches) Hintergrundwissen für eine fundierte Würdigung der Methodik. Man muss den Autoren ein Kompliment machen dafür, dass sie die Methodik in einem Anhang etwas näher beschreiben. (Veröffentlichung der Rohdaten wäre noch besser gewesen).
Ein Einwand, der auf viele ähnliche Reports zutrifft: Aus einer relativ schmalen Datenbasis (ca. 1000 Leute, die im Schnitt 31 Fragen beantwortet haben) werden Dutzende von Aussagen abgeleitet. Jeder einzelne (statistisch signifikante) Unterschied wird herangezogen und plausibel gemacht. So glaube ich, dass die Aussage “Die Branche Retail hat bessere SDO Performance” (Seite 19) mit Vorsicht zu genießen ist, sie entspricht jedenfalls nicht meiner (unrepräsentativen) Erfahrung. Es wurden 13 Branchen erfasst, und nur das Merkmal “Branchenzugehörigkeit: Retail” hatte einen statistisch signifikanten Einfluss auf die Performance. Die statistische Auswertung ist so angelegt, dass eine von 20 Branchenzugehörigkeiten “falsch positiv” sein kann (p<0,05), d.h. man sieht Unterschiede, die nur zufällig durch die Wahl der Stichprobe bedingt sind. Es ist also gar nicht so unwahrscheinlich (48,6%), dass eine oder mehrere Branchen statistisch signifikant werden, obwohl Branchenzugehörigkeit “in Wirklichkeit” keinen Einfluss hat. Das Phänomen ist unter dem Stichwort Mehrfaches Testen bekannt.
Das Problem von falsch positiven Befunden liegt in der Natur der statistischen Methoden. Was mich nur manchmal stört, ist die mutige Interpretation: Die ganze Seite 32 “Excel or Die” erklärt den Konkurrenzdruck zur Ursache für die bessere Software Delivery and Operational Performance des Handels. Wer weiß, was die Erklärung gewesen wäre, wenn zufällig die Branchenzugehörigkeit “Financial Services” signifikant geworden wäre. Auch die Beziehung im Diagramm auf Seite 57 “Monitoring → Technical debt”, d.h. besseres Monitoring verringern technische Schulden, scheint mir zweifelhaft. Ich kann einfach keine plausible Erklärung dafür finden.
Fazit
Der Report “Accelerate - State of DevOps 2019” gibt Denkanstöße zur Verbesserung der eigenen Fähigkeiten und leistet Hilfe bei der internen Überzeugungsarbeit. Die empirischen Befunde stimmen gut mit dem aktuellen Wissensstand überein. Der Report hält, was er verspricht: man bekommt einen umfassenden Überblick über den aktuellen Stand von DevOps. Klare Leseempfehlung.
Matthias Berth